# 整体流程
一直想自己写一个简单的秒杀架构的演变,加强自己,参考了很多博客和文章,如有不正确的地方请指出,感谢😋
地址
- Github:https://github.com/dolyw/SeckillEvolution (opens new window)
- Gitee(码云):https://gitee.com/dolyw/SeckillEvolution (opens new window)
- 0. 整体流程
- 1. 传统方式
- 2. 使用乐观锁
- 3. 使用缓存
- 4. 使用分布式限流
- 5. 使用队列异步下单
# 1. 常见场景
最典型的就是淘宝京东等电商双十一秒杀了,短时间上亿的用户涌入,瞬间流量巨大(高并发)。例如,200万人准备在凌晨12:00准备抢购一件商品,但是商品的数量是有限的100件,这样真实能购买到该件商品的用户也只有100人及以下,不能卖超
但是从业务上来说,秒杀活动是希望更多的人来参与,也就是抢购之前希望有越来越多的人来看购买商品,但是,在抢购时间达到后,用户开始真正下单时,秒杀的服务器后端却不希望同时有几百万人同时发起抢购请求
我们都知道服务器的处理资源是有限的,所以出现峰值的时候,很容易导致服务器宕机,用户无法访问的情况出现,这就好比出行的时候存在早高峰和晚高峰的问题,为了解决这个问题,出行就有了错峰限行的解决方案
同理,在线上的秒杀等业务场景,也需要类似的解决方案,需要平安度过同时抢购带来的流量峰值的问题,这就是流量削峰的由来
# 2. 流量削峰
削峰从本质上来说就是更多地延缓用户请求,以及层层过滤用户的访问需求,遵从最后落地到数据库的请求数要尽量少的原则
流量削峰主要有三种操作思路(排队,答题,过滤),简单说下
排队最容易想到的解决方案就是用消息队列来缓冲瞬时流量,把同步的直接调用转换成异步的间接推送,中间通过一个队列在一端承接瞬时的流量洪峰,在另一端平滑地将消息推送出去,在这里,消息队列就像水库一样,拦蓄上游的洪水,削减进入下游河道的洪峰流量,从而达到减免洪水灾害的目的
答题目的其实就是延缓请求,起到对请求流量进行削峰的作用,从而让系统能够更好地支持瞬时的流量高峰
前面介绍的排队和答题,要么是在接收请求时做缓冲,要么是减少请求的同时发送,而针对秒杀场景还有一种方法,就是对请求进行分层过滤,从而过滤掉一些无效的请求,从Web层接到请求,到缓存,消息队列,最终到数据库这样就像漏斗一样,尽量把数据量和请求量一层一层地过滤和减少了,最终,到漏斗最末端(数据库)的才是有效请求
# 3. 项目准备
# 3.1. 表结构
这里我采用的是MySQL,简单的使用两个表,一个库存表,一个订单表,插入一条商品数据
--- 删除数据库
drop database seckill;
--- 创建数据库
create database seckill;
--- 使用数据库
use seckill;
--- 创建库存表
DROP TABLE IF EXISTS `t_seckill_stock`;
CREATE TABLE `t_seckill_stock` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '库存ID',
`name` varchar(50) NOT NULL DEFAULT 'OnePlus 7 Pro' COMMENT '名称',
`count` int(11) NOT NULL COMMENT '库存',
`sale` int(11) NOT NULL COMMENT '已售',
`version` int(11) NOT NULL COMMENT '乐观锁,版本号',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='库存表';
--- 插入一条商品,初始化10个库存
INSERT INTO `t_seckill_stock` (`count`, `sale`, `version`) VALUES ('10', '0', '0');
--- 创建库存订单表
DROP TABLE IF EXISTS `t_seckill_stock_order`;
CREATE TABLE `t_seckill_stock_order` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`stock_id` int(11) NOT NULL COMMENT '库存ID',
`name` varchar(30) NOT NULL DEFAULT 'OnePlus 7 Pro' COMMENT '商品名称',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='库存订单表';
# 3.2. 工程创建
这个自行创建即可,我创建的是一个SpringBoot2项目,然后使用代码生成工具: ViewGenerator (opens new window),根据表结构生成一下对应的文件,记得移除表前缀参数t_seckill_
使用通用Mapper要在Application处加个注解@tk.mybatis.spring.annotation.MapperScan
@SpringBootApplication
@tk.mybatis.spring.annotation.MapperScan("com.example.dao")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
SpringBoot2连接MySQLurl属性要配置serverTimezone=GMT%2B8,driver-class-name属性要改为com.mysql.cj.jdbc.Driver
server:
port: 8080
spring:
datasource:
name: SeckillEvolution
url: jdbc:mysql://127.0.0.1:3306/seckill?serverTimezone=GMT%2B8&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: root
# 使用Druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
druid:
filters: stat
maxActive: 20
initialSize: 1
maxWait: 60000
minIdle: 1
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: select 'x'
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
maxOpenPreparedStatements: 20
# 404交给异常处理器处理
mvc:
throw-exception-if-no-handler-found: true
# 404交给异常处理器处理
resources:
add-mappings: false
mybatis:
# Mybatis配置Mapper路径
mapper-locations: classpath:mapper/*.xml
# Mybatis配置Model类对应
type-aliases-package: com.example.dto.custom
pagehelper:
params: count=countSql
# 指定分页插件使用哪种方言
helper-dialect: mysql
# 分页合理化参数 pageNum<=0时会查询第一页 pageNum>pages(超过总数时) 会查询最后一页
reasonable: 'true'
support-methods-arguments: 'true'
mapper:
# 通用Mapper的insertSelective和updateByPrimaryKeySelective中是否判断字符串类型!=''
not-empty: true
logging:
# Debug打印SQL
level.com.example.dao: debug
# 3.3. 初始代码
先编写一个入口Controller,默认有一个初始化库存方法
- SeckillEvolutionController
/**
* 一个简单的秒杀架构的演变
*
* @author wliduo[i@dolyw.com]
* @date 2019/11/20 19:49
*/
@RestController
@RequestMapping("/seckill")
public class SeckillEvolutionController {
/**
* logger
*/
private static final Logger logger = LoggerFactory.getLogger(SeckillEvolutionController.class);
private final IStockService stockService;
private final IStockOrderService stockOrderService;
private final ISeckillEvolutionService seckillEvolutionService;
/**
* 构造注入
* @param stockService
* @param stockOrderService
*/
@Autowired
public SeckillEvolutionController(IStockService stockService, IStockOrderService stockOrderService,
ISeckillEvolutionService seckillEvolutionService) {
this.stockService = stockService;
this.stockOrderService = stockOrderService;
this.seckillEvolutionService = seckillEvolutionService;
}
/**
* 初始化库存数量
*/
private static final Integer ITEM_STOCK_COUNT = 10;
/**
* 初始化卖出数量,乐观锁版本
*/
private static final Integer ITEM_STOCK_SALE = 0;
/**
* 初始化库存数量
*
* @param id 商品ID
* @return com.example.common.ResponseBean
* @throws
* @author wliduo[i@dolyw.com]
* @date 2019/11/22 15:59
*/
@PutMapping("/init/{id}")
public ResponseBean init(@PathVariable("id") Integer id) {
// 更新库存表该商品的库存,已售,乐观锁版本号
StockDto stockDto = new StockDto();
stockDto.setId(id);
stockDto.setName(Constant.ITEM_STOCK_NAME);
stockDto.setCount(ITEM_STOCK_COUNT);
stockDto.setSale(ITEM_STOCK_SALE);
stockDto.setVersion(ITEM_STOCK_SALE);
stockService.updateByPrimaryKey(stockDto);
// 删除订单表该商品所有数据
StockOrderDto stockOrderDto = new StockOrderDto();
stockOrderDto.setStockId(id);
stockOrderService.delete(stockOrderDto);
return new ResponseBean(HttpStatus.OK.value(), "初始化库存成功", null);
}
}
再创建一个Service提供流程使用
- ISeckillEvolutionService
package com.example.service;
/**
* ISeckillEvolutionService
*
* @author wliduo[i@dolyw.com]
* @date 2019-11-20 18:03:33
*/
public interface ISeckillEvolutionService {
}
- SeckillEvolutionServiceImpl
/**
* StockServiceImpl
*
* @author wliduo[i@dolyw.com]
* @date 2019-11-20 18:03:33
*/
@Service("seckillEvolutionService")
public class SeckillEvolutionServiceImpl implements ISeckillEvolutionService {
}
最后提供一个秒杀接口以供实现
- ISeckillService
package com.example.seckill;
import com.example.dto.custom.StockDto;
/**
* 统一接口
*
* @author wliduo[i@dolyw.com]
* @date 2019-11-20 18:03:33
*/
public interface ISeckillService {
/**
* 检查库存
*
* @param id
* @return com.example.dto.custom.StockDto
* @throws
* @author wliduo[i@dolyw.com]
* @date 2019/11/20 20:22
*/
StockDto checkStock(Integer id);
/**
* 扣库存
*
* @param stockDto
* @return java.lang.Integer 操作成功条数
* @throws
* @author wliduo[i@dolyw.com]
* @date 2019/11/20 20:24
*/
Integer saleStock(StockDto stockDto);
/**
* 下订单
*
* @param stockDto
* @return java.lang.Integer 操作成功条数
* @throws
* @author wliduo[i@dolyw.com]
* @date 2019/11/20 20:26
*/
Integer createOrder(StockDto stockDto);
}
# 4. 思路流程
一般的秒杀流程从后台接收到请求开始不外乎是这样的(这里不考虑前端的答题,验证码等流程,直接以最终后端下单的请求开始)
- 用户通过前端校验最终发起请求到后端
- 然后校验库存,扣库存,创建订单
- 最终数据落地,持久化保存
# 4.1. 传统方式
我们首先搭建一个后台服务接口(实现校验库存,扣库存,创建订单),不做任何限制,使用JMeter,模拟500个并发线程测试购买10个库存的商品,地址: 1. 传统方式
可以发现并发事务下会出现错误,出现卖超问题,这是因为同一时间大量线程同时请求校验库存,扣库存,创建订单,这三个操作不在同一个原子,比如,很多线程同时读到库存为10,这样都穿过了校验库存的判断,所以出现卖超问题
在这种情况下就引入了锁的概念,锁区分为乐观锁和悲观锁,悲观锁都是牺牲性能保证数据,所以在这种高并发场景下,一般都是使用乐观锁解决
# 4.2. 使用乐观锁
我们再搭建一个后台服务接口(实现校验库存,扣库存,创建订单),但是这次我们需要使用乐观锁,这里可以先查看一篇文章: MySQL那些锁 (opens new window)
使用JMeter,模拟500个并发线程测试购买10个库存的商品,地址: 2. 使用乐观锁
可以发现乐观锁解决卖超问题,多个线程同时在检查库存的时候都会拿到当前商品的相同乐观锁版本号,然后在扣库存时,如果版本号不对,就会扣减失败,抛出异常结束,这样每个版本号就只能有第一个线程扣库存操作成功,其他相同版本号的线程秒杀失败,就不会存在卖超问题了
不过现在每次读取库存都去查数据库,我们可以看下Druid的监控,地址: http://localhost:8080/druid/sql.html (opens new window)
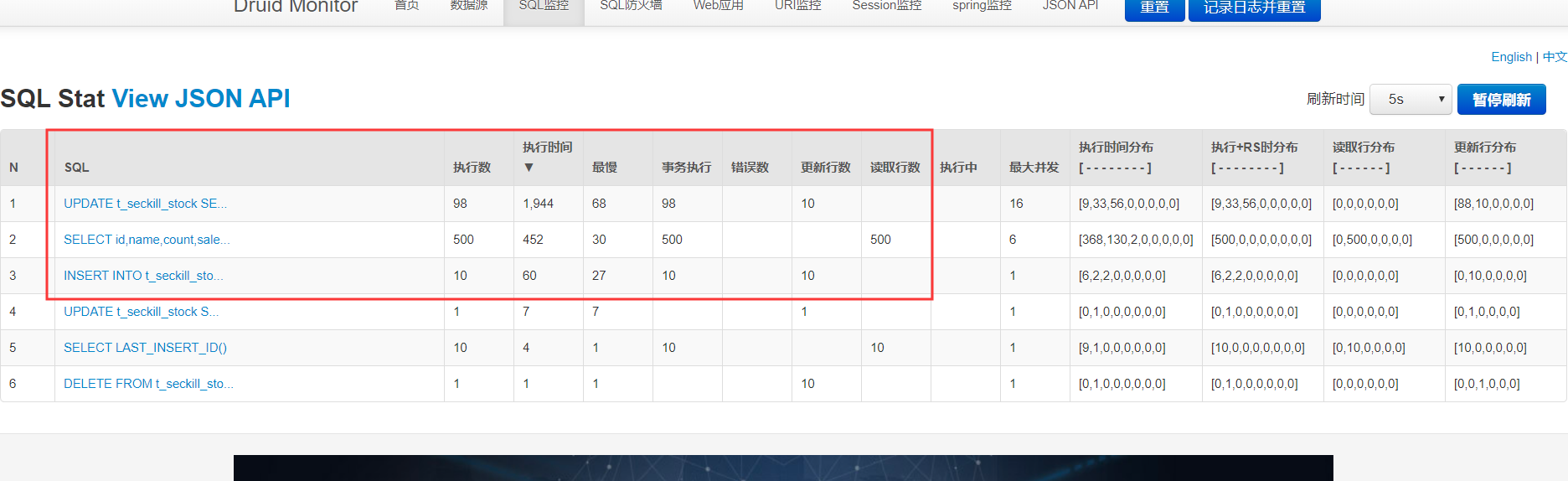
可以看到,查询库存执行了500次,遵从最后落地到数据库的请求数要尽量少的原则,其实我们可以把这个数据放缓存,提升性能
# 4.3. 使用缓存
我们继续搭建一个后台服务接口(实现校验库存,扣库存,创建订单),这次我们引入缓存,这里可以先查看一篇文章: Redis与数据库一致性 (opens new window)
这里我采用的是先更新数据库再更新缓存,因为这里缓存数据计算简单,只需要进行加减一即可,所以我们直接进行更新缓存
这次主要改造是检查库存和扣库存方法,检查库存直接去Redis获取,不再去查数据库,而在扣库存这里本身是使用的乐观锁操作,只有操作成功(扣库存成功)的才需要更新缓存数据
使用JMeter,模拟500个并发线程测试购买10个库存的商品,地址: 3. 使用缓存
我们可以看下使用缓存后Druid的监控,地址: http://localhost:8080/druid/sql.html (opens new window)
使用了缓存,可以看到库存查询SQL,只执行了一次,就是缓存预热那执行了一次,不像之前每次库存都去查数据库
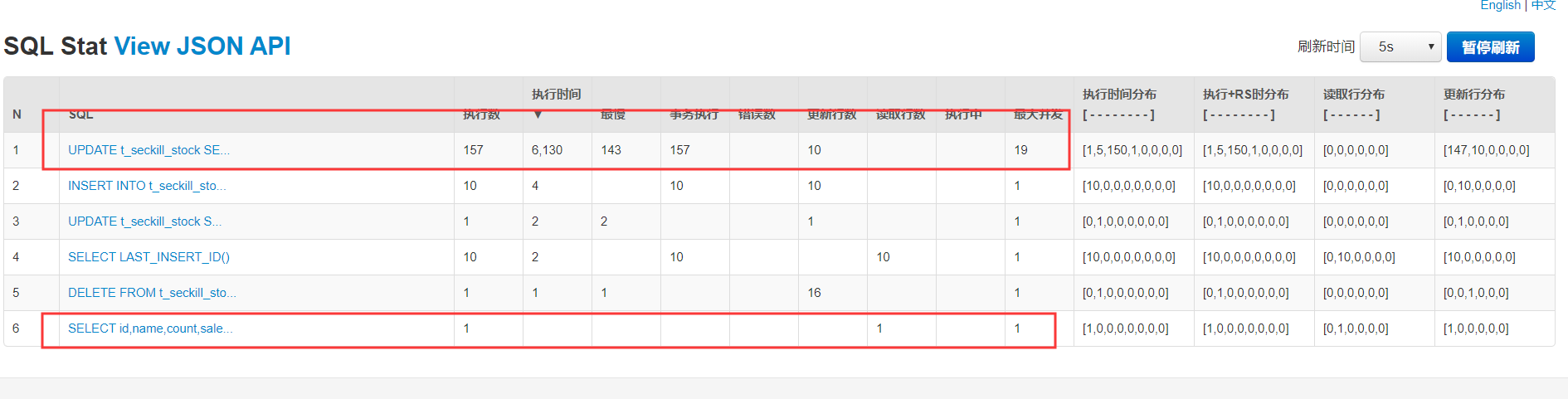
不过乐观锁更新操作还是执行了157次SQL,遵从最后落地到数据库的请求数要尽量少的原则,有没有办法优化这里呢,可以的,实际上很多都是无效请求,这里我们可以使用限流,把大部分无效请求拦截了,尽可能保证最终到达数据库的都是有效请求
# 4.4. 使用分布式限流
我们继续搭建一个后台服务接口(实现校验库存,扣库存,创建订单),这次我们引入限流,这里可以先查看一篇文章: 高并发下的限流分析 (opens new window)
使用JMeter,模拟500个并发线程测试购买10个库存的商品,地址: 4. 使用分布式限流
我们可以看下 Druid 的监控,地址: http://localhost:8080/druid/sql.html (opens new window)
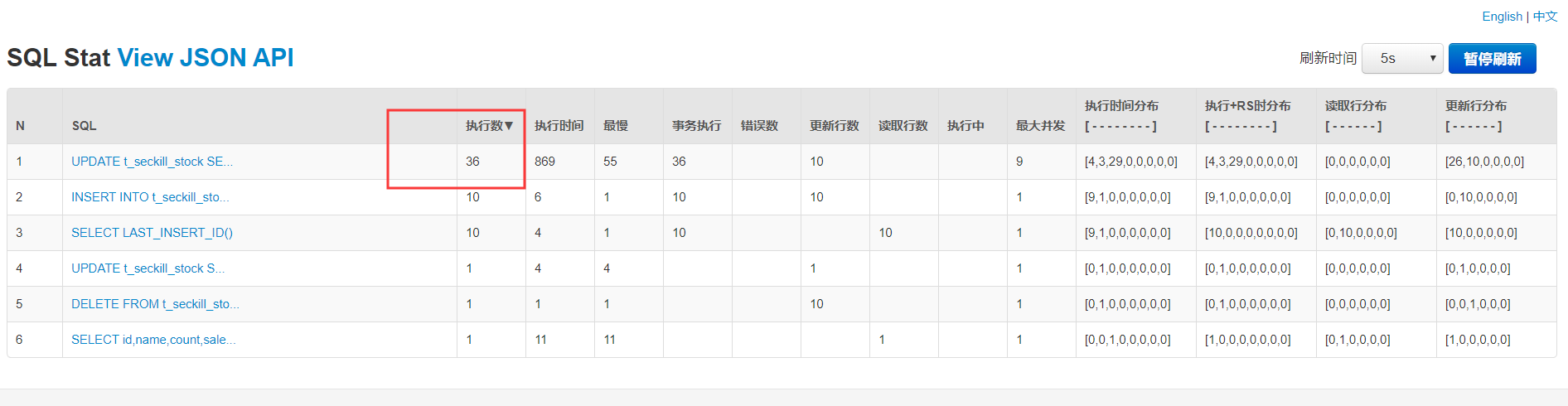
使用了限流,可以看到乐观锁更新不像之前那样执行 157 次了,只执行了 36 次,很多请求直接被限流了,我们看下后台日志,可以看到很多请求直接被限流限制了,这样就达到了我们的目的
# 4.5. 使用队列异步下单
那我们还可以怎么优化提高吞吐量以及性能呢,我们上文所有例子其实都是同步请求,完全可以利用同步转异步来提高性能,这里我们将下订单的操作进行异步化,利用消息队列来进行解耦,这样可以让 DB 异步执行下单
每当一个请求通过了限流和库存校验之后就将订单信息发给消息队列,这样一个请求就可以直接返回了,消费程序做下订单的操作,对数据进行入库落地,因为异步了,所以最终需要采取回调或者是其他提醒的方式提醒用户购买完成
地址: 5. 使用队列异步下单