# Redis与数据库一致性
Redis与数据库一致性的总结,参考了很多博客和文章,如有不正确的地方请指出,感谢😋
先做一个说明,从理论上来说,给缓存设置过期时间,是可以保证最终一致性的解决方案,这种方案下,我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可,也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存,所以接下来的方案是保障缓存与数据库数据能尽可能的更快一致
根据缓存是删除还是更新,以及操作顺序大概是可以分为下面四种情况
- 先更新数据库,再更新缓存
- 先更新缓存,再更新数据库
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
正常来说为了保证原子性,出现异常只可能出现第一步执行成功,第二步执行失败继续执行重试机制的情况,如果第一步就失败了该请求应该就直接结束
# 更新缓存 VS 删除缓存
这里我们简单对比一下,更新缓存 VS 删除缓存
- 什么是更新缓存: 数据不但写入数据库,还会写入缓存
- 什么是删除缓存: 数据只会写入数据库,不会写入缓存,只会删除缓存
优点对比
- 更新缓存的优点: 缓存不会增加一次Miss,命中率高
- 删除缓存的优点: 操作简单,能防止更新出现的线程安全问题
那到底是选择更新缓存还是删除缓存呢,主要取决于更新缓存的复杂度
- 更新缓存的代价很小,此时我们应该更倾向于更新缓存,以保证更高的缓存命中率
- 更新缓存的代价很大,此时我们应该更倾向于删除缓存
例如
- 只是简单的更新一下用户余额,只操作一个字段,那就可以采用更新缓存
- 还有类似秒杀下商品库存数量这种并发下查询频繁的数据,也可以使用更新缓存
不过这种更新数值,要注意线程安全的问题,防止产生脏数据
主要还是要以业务场景为主进行选择
不过大部分场景下删除缓存操作简单,并且带来的副作用只是增加了一次Cache Miss,建议作为通用的处理方式
# 先更新数据库,再更新缓存
这种方式就适合更新缓存的代价很小的数据,例如上面说的余额,库存数量这类数据,不过要注意线程安全的问题
线程安全角度
同时有请求A和请求B进行更新操作,那么会出现
- 线程A更新了数据库
- 线程B更新了数据库
- 线程B更新了缓存
- 线程A更新了缓存
这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存,这就导致了脏数据
业务场景角度
- 有如下两种不适合场景
- 如果你是一个写数据库场景比较多,而读数据场景比较少的业务需求,采用这种方案就会导致,数据压根还没读到,缓存就被频繁的更新,浪费性能
- 如果你写入数据库的值,并不是直接写入缓存的,而是要经过一系列复杂的计算再写入缓存。那么,每次写入数据库后,都再次计算写入缓存的值,无疑是也浪费性能的
# 先更新缓存,再更新数据库
本来这种情况应该是和第一种情况一样会存在线程安全问题的,但是这种情况是有人使用过的,根据书籍《淘宝技术这十年》里,多隆把商品详情页放入缓存,采取的正是先更新缓存,再将缓存中的数据异步更新到数据库这种方式,有兴趣了解的可以查看这篇博客: https://www.cnblogs.com/rjzheng/p/9240611.html (opens new window)
还有现在互联网常见的点赞功能,也可以采用这种方式,有兴趣了解的可以查看这篇文章: https://juejin.im/post/5bdc257e6fb9a049ba410098 (opens new window)
# 先删除缓存,再更新数据库
简单的想一下,好像这种方式不错,就算是第一步删除缓存成功,第二步写数据库失败,则只会引发一次Cache Miss,对数据没有影响,其实仔细一想并发下也很容易导致了脏数据,例如
- 请求A进行写操作,删除缓存
- 请求B查询发现缓存不存在
- 请求B去数据库查询得到旧值
- 请求B将旧值写入缓存
- 请求A将新值写入数据库
那怎么解决呢,不着急,先看第四种情况,后面再统一说第三种和第四种的解决方案
# 先更新数据库,再删除缓存
先说一下,老外提出了一个缓存更新套路,名为Cache-Aside Pattern (opens new window)

- 更新操作就是先更新数据库,再删除缓存
- 读取操作先从缓存取数据,没有,则从数据库中取数据,成功后,放到缓存中
这是标准的设计方案,包括Facebook的论文Scaling Memcache at Facebook (opens new window)也使用了这个策略
为什么他们都用这种方式呢,这种情况不存在并发问题么?
答案是也存在,但是出现概率比第三种低,例如
- 请求缓存刚好失效
- 请求A查询数据库,得一个旧值
- 请求B将新值写入数据库
- 请求B删除缓存
- 请求A将查到的旧值写入缓存
这样就出现脏数据了,然而,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作删除缓存,所有的这些条件都具备的概率基本并不大,但是还是会有出现的概率
并且假如第一步写数据库成功,第二步删除缓存失败,这样也导致脏数据,请看解决方案
# 解决方案
那怎么解决呢,可以采用延时双删策略(缓存双淘汰法),可以将前面所造成的缓存脏数据,再次删除
- 先删除(淘汰)缓存
- 再写数据库(这两步和原来一样)
- 休眠1秒,再次删除(淘汰)缓存
或者是
- 先写数据库
- 再删除(淘汰)缓存(这两步和原来一样)
- 休眠1秒,再次删除(淘汰)缓存
这个1秒应该看你的业务场景,应该自行评估自己的项目的读数据业务逻辑的耗时,然后写数据的休眠时间则在读数据业务逻辑的耗时基础上,加几百ms即可,这么做确保读请求结束,写请求可以删除读请求造成的缓存脏数据
如果你用了MySql的读写分离架构怎么办?,例如
- 请求A进行写操作,删除缓存
- 请求A将数据写入数据库了,(或者是先更新数据库,后删除缓存)
- 请求B查询缓存发现,缓存没有值
- 请求B去从库查询,这时,还没有完成主从同步,因此查询到的是旧值
- 请求B将旧值写入缓存
- 数据库完成主从同步,从库变为新值
这种情景,就是数据不一致的原因,还是采用延时双删策略(缓存双淘汰法),只是,休眠时间修改为在主从同步的延时时间基础上,加几百ms
并且为了性能更快,可以把第二次删除缓存可以做成异步的,这样不会阻塞请求了,如果再严谨点,防止第二次删除缓存失败,这个异步删除缓存可以加上重试机制,失败一直重试,直到成功
这里给出两种重试机制参考
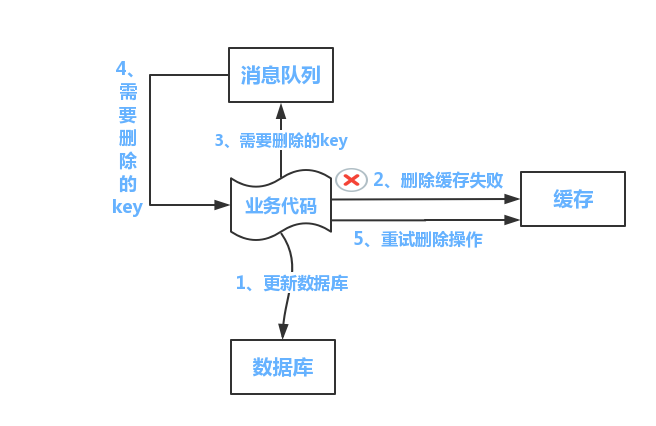
方案一
- 更新数据库数据
- 缓存因为种种问题删除失败
- 将需要删除的key发送至消息队列
- 自己消费消息,获得需要删除的key
- 继续重试删除操作,直到成功
然而,该方案有一个缺点,对业务线代码造成大量的侵入,于是有了方案二,启动一个订阅程序去订阅数据库的Binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作
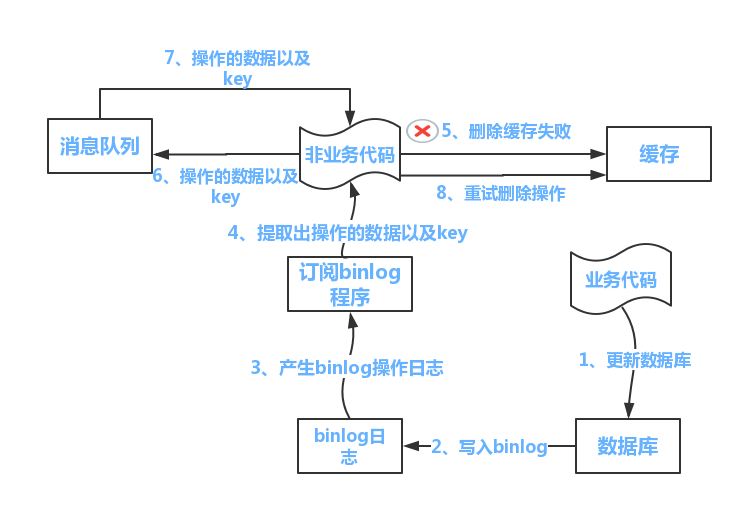
方案二
- 更新数据库数据
- 数据库会将操作信息写入binlog日志当中
- 订阅程序提取出所需要的数据以及key
- 另起一段非业务代码,获得该信息
- 尝试删除缓存操作,发现删除失败
- 将这些信息发送至消息队列
- 重新从消息队列中获得该数据,重试操作
上述的订阅Binlog程序在MySql中有现成的中间件叫Canal,可以完成订阅Binlog日志的功能,另外,重试机制,这里采用的是消息队列的方式。如果对一致性要求不是很高,直接在程序中另起一个线程,每隔一段时间去重试即可,这些大家可以灵活自由发挥,只是提供一个思路
# 最后的总结
大部分应该使用的都是第三种或第四种方式,如果都是采用延时双删策略(缓存双淘汰法),可能区别不会很大,不过第四种方式出现脏数据概率是更小点,更多的话还是要结合自身业务场景使用,自己灵活变通
参考